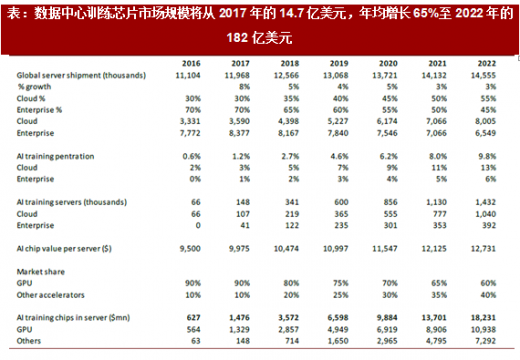
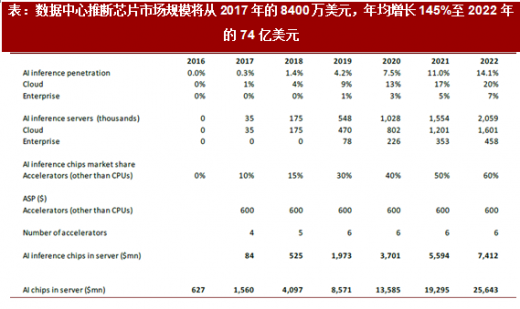
我们预期,数据中心AI 芯片的市场规模将从2017 年的15.6 亿美元,年均增长75%至2022的256 亿美元。其中训练芯片182 亿,推断芯片(除CPU 以外)74 亿。训练芯片市场已出现高速增长,而对推断加速器的需求也将于今/明年爆发。
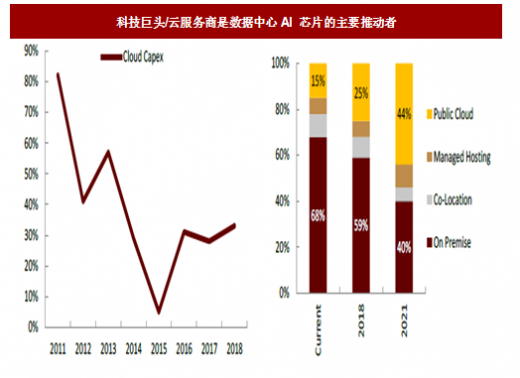
科技巨头/云服务商是数据中心AI 芯片的主要推动者。自2012 年以来,人工智能领域的研究和产业投资出现了加速发展,Alphabet、亚马逊、微软、Facebook 等科技巨头视人工智能为下一个十年科技进步的重要支柱(参见2015 年报告《泡沫启示录:人工智能,魔鬼还是忠仆?》)。往前看,随着云计算的加速普及,和云服务商资本开支维持高位,云数据中心将持续是AI 训练芯片的最大购买者。我们估计,云数据中心服务器中,AI 训练芯片的渗透率将从目前的3%左右提高到2022 年的13%。
各行业企业对人工智能的应用也在启动,或本地部署或云上调用。在美国,金融、医疗、汽车交通和工业制造是人工智能最先落地的企业级市场。这些领域的大公司有在本地数据中心内部署AI 加速芯片以训练自己模型的需求。当然,更多行业和中小企业将主要借助公有云服务商提供的工具,在云端调用计算实例(instance)和API,进行二次开发。我们估计,企业本地数据中心服务器中,AI 训练芯片的渗透率可从今年的0.5%,提高到2022 年的6%。
数据中心也将承担部分的算法推断任务。深度学习的过程主要分为训练(Train)和推断(Inference)两步。一般来说,训练的数据量更大、复杂度更高,是通过向深度神经网络输入大批量标签好的数据,经过对模型中权重参数的逐渐优化,尽量达到模型的输出判断与输入标签一致;推断则是向训练好的模型中输入新数据,利用优化过的权重参数对数据的特征或属性进行推理并做出判断。训练过程对算力的要求,使算法训练主要发生在数据中心内。而就推断而言,虽然我们认为大部分的推断任务将由智能终端完成,但数据中心也将承担部分推断,特别是对算力和存储要求较高的高强度推断,或者其算法还需要在运用中频繁加以迭代改进。此外,为了控制终端设备的成本,也会将推断置于云端(如目前的亚马逊Echo 智能音箱)。当前数据中心推断工作量主要由CPU 兼任,但我们预期,推断加速器需求将于今/明年爆发,在云服务器和企业本地服务器上的渗透率到2022 年分别达到20%/7%。
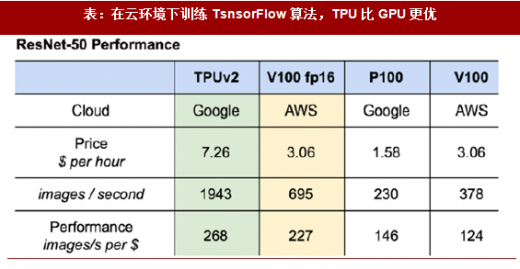
xPU 挑战GPU。英伟达数据中心收入已从2017 财年(1 月止)的8.3 亿美元,增长133%至2018 财年的19.32 亿。GPU 强大的并行计算能力在深度学习训练环节的优势已是市场共识。英伟达经过多年努力形成的生态系统(Cuda 已到第9 代,开发者51.1 万,支持TensorFlow/Caffe2/MXNet 等多个主流框架,扶持创业企业1300 家,开源Xavier DLA)也构成了较好的先发优势。然而,谷歌TPU 在TensorFlow 框架下算法的推断和训练,性能已经优于GPU。我们认为,随着市场规模的扩大,英伟达一家独占的局面势必改变。我们目前假设英伟达GPU在训练环节的市场份额,从2017 年的90%,下降到2022 年的60%,在推断环节的市场份额,可能从初始的60%下降到30%。
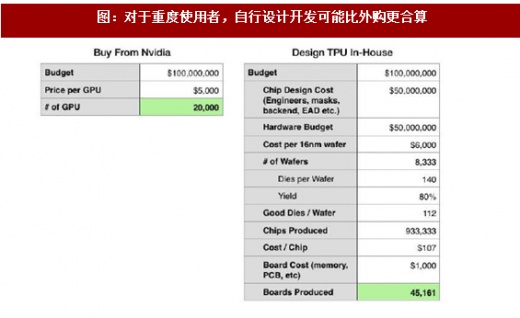
除谷歌外,亚马逊、微软等都有动力开发自己的AI 芯片。作为AI 的重度用户,自行开发设计芯片,可能并不比大量采购自英伟达昂贵。自行设计还可排除GPU 上不必要的功能特征,优化功耗。当然,出自差异化自身基础设施和云服务产品的初衷,这些公司不大可能出售芯片,而只会允许第三方开发者通过云端调用的方式使用。
GPU 做推断,可能大材小用。英伟达也在大力发展推断业务。自去年5 月硅谷GTC大会上宣布推出推理加速器TensorRT 以来,已有超过1200 家客户企业开始使用。TensorRT 3 适配于Volta GPU,在7ms 延迟下,可使V100 相比P100 的推理速度提高3.7 倍,并可使在V100 上优化和部署TensorFlow 模型,比其自带的推理框架,速度提高18 倍。然而,GPU 的功耗和价格,可能对很多推断工作量来说,缺乏经济性。
FPGAs 有低功耗、低延迟、定制化的优点。FPGAs 平均每瓦特的性能在图片CNN 算法推理、语音LSTM 算法推理上,比CPU 分别提高30/81 倍。英特尔的FPGA 已被微软Azure 采用,赛灵思已被亚马逊云、百度云和华为采用。新任赛灵思CEO 对数据中心业务的重视程度超过前任,预计2019 年可贡献显著增长,2020 年收入可超过3亿美元。(对FPGAs 及其与GPU 区别的详细介绍,参见《寻找AI+淘金热中的卖水人》)
可能出现整合方案。英特尔已推出了FPGAs 加CPU 的整合方案(Xeon + Altera Arria10),公司还近期宣布重新进入分立GPU 市场,不排除未来针对数据中心AI 服务器,推出GPU 加CPU 的整合方案。整合方案至少可以减少体积。
参考观研天下发布《2018年中国AI芯片行业分析报告-市场运营态势与发展前景研究》
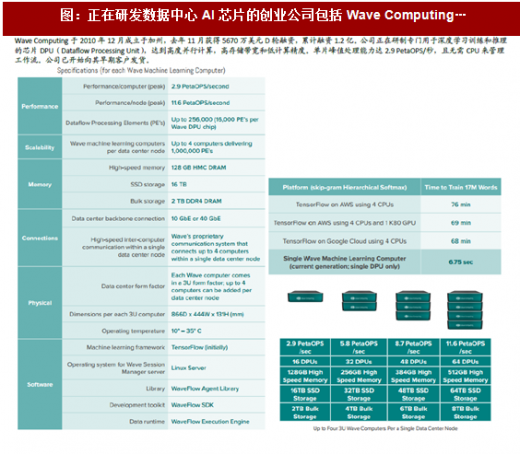
创投活跃。芯片业因其高昂的开发成本、较长的产品导入期和较高的失败率,本是VC 投资较少的领域。但AI 所可能引发的革命性变化,使AI 芯片的创业投资格外活跃。在服务器AI 芯片上,我们看到Wave Computing、Graphcore、Cerebras Systems、Groq 等已经或即将推出第一代产品。相比GPU,这些创业公司专门针对深度学习/人工智能算法训练和推理开发的xPU,可能具备更高的计算效率、能量效率和可编程性。当然,我们也预期,这些创业公司如能成功打造出被业界认可的AI 加速器,将成为大公司的收购标的。
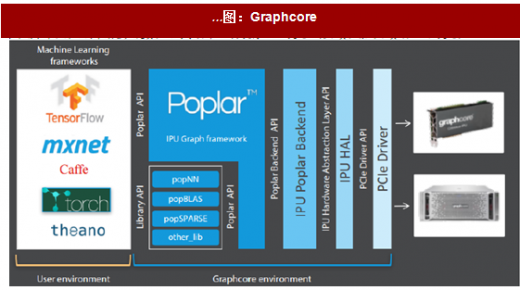
Graphcore 成立于2016 年,总部位于英国,其团队成员来自Altera(被英特尔收购)和Icera(被英伟达收购)。公司的产品主要是IPU(Intelligent ProcessingUnit)处理器,该处理器经过优化,可以高效的处理机器学习领域中极其复杂的高维模型。IPU 强调大规模并行运算和低精度浮点运算,与其它解决方案相比,IPU 拥有更高的计算密度以及超过100 倍的内存带宽,可以完全在内部处理机器学习模型,拥有更低的能耗与性能。IPU 产品包括IPU设备与IPU 加速器,前者旨在为云和企业数据中心服务,帮助加速AI 应用并降低成本,并将训练和推理环节提速10x 和100x;后者是一个PCle 卡,能够插入服务器中以加速机器学习应用。公司还为主流机器学习框架例如TensorFlow 和MXNet 提供无缝界面。为了支持该界面,Graphcore 推出了灵活的开源图形编程软件框架Poplar,其中包含工具、驱动及应用库,使用C++或Python 界面,允许开发人员修改和扩展库,从而更快更方便的使用IPU 系统。公司表示,其产品可以让客户在同一芯片上进行训练和推理,例如白天进行推理(算法执行),夜间利用当日获得的新数据对算法进行再训练。公司计划今年初开始向早期客户发货。公司于去年11 月获得5000 美元C 轮融资,累计融资额1.1 亿美元。
 Cerebras Systems 成立于2016 年,总部位于加州Los Altos,目前正在研制下一代用于深度学习训练的芯片。Cerebras 的官网上将自己描述为一家低调的初创企业,敢于解决别人无法解决的问题。该公司的CEO Andrew Feldman 和CTO Gary Lauterbach 此前都是SeaMicro 的联合创始人,在SeaMicro 被收购后加入了AMD。公司目前经过2 轮共融资5200 万美元。
Cerebras Systems 成立于2016 年,总部位于加州Los Altos,目前正在研制下一代用于深度学习训练的芯片。Cerebras 的官网上将自己描述为一家低调的初创企业,敢于解决别人无法解决的问题。该公司的CEO Andrew Feldman 和CTO Gary Lauterbach 此前都是SeaMicro 的联合创始人,在SeaMicro 被收购后加入了AMD。公司目前经过2 轮共融资5200 万美元。
科技巨头/云服务商是数据中心AI 芯片的主要推动者。自2012 年以来,人工智能领域的研究和产业投资出现了加速发展,Alphabet、亚马逊、微软、Facebook 等科技巨头视人工智能为下一个十年科技进步的重要支柱(参见2015 年报告《泡沫启示录:人工智能,魔鬼还是忠仆?》)。往前看,随着云计算的加速普及,和云服务商资本开支维持高位,云数据中心将持续是AI 训练芯片的最大购买者。我们估计,云数据中心服务器中,AI 训练芯片的渗透率将从目前的3%左右提高到2022 年的13%。
各行业企业对人工智能的应用也在启动,或本地部署或云上调用。在美国,金融、医疗、汽车交通和工业制造是人工智能最先落地的企业级市场。这些领域的大公司有在本地数据中心内部署AI 加速芯片以训练自己模型的需求。当然,更多行业和中小企业将主要借助公有云服务商提供的工具,在云端调用计算实例(instance)和API,进行二次开发。我们估计,企业本地数据中心服务器中,AI 训练芯片的渗透率可从今年的0.5%,提高到2022 年的6%。
数据中心也将承担部分的算法推断任务。深度学习的过程主要分为训练(Train)和推断(Inference)两步。一般来说,训练的数据量更大、复杂度更高,是通过向深度神经网络输入大批量标签好的数据,经过对模型中权重参数的逐渐优化,尽量达到模型的输出判断与输入标签一致;推断则是向训练好的模型中输入新数据,利用优化过的权重参数对数据的特征或属性进行推理并做出判断。训练过程对算力的要求,使算法训练主要发生在数据中心内。而就推断而言,虽然我们认为大部分的推断任务将由智能终端完成,但数据中心也将承担部分推断,特别是对算力和存储要求较高的高强度推断,或者其算法还需要在运用中频繁加以迭代改进。此外,为了控制终端设备的成本,也会将推断置于云端(如目前的亚马逊Echo 智能音箱)。当前数据中心推断工作量主要由CPU 兼任,但我们预期,推断加速器需求将于今/明年爆发,在云服务器和企业本地服务器上的渗透率到2022 年分别达到20%/7%。
xPU 挑战GPU。英伟达数据中心收入已从2017 财年(1 月止)的8.3 亿美元,增长133%至2018 财年的19.32 亿。GPU 强大的并行计算能力在深度学习训练环节的优势已是市场共识。英伟达经过多年努力形成的生态系统(Cuda 已到第9 代,开发者51.1 万,支持TensorFlow/Caffe2/MXNet 等多个主流框架,扶持创业企业1300 家,开源Xavier DLA)也构成了较好的先发优势。然而,谷歌TPU 在TensorFlow 框架下算法的推断和训练,性能已经优于GPU。我们认为,随着市场规模的扩大,英伟达一家独占的局面势必改变。我们目前假设英伟达GPU在训练环节的市场份额,从2017 年的90%,下降到2022 年的60%,在推断环节的市场份额,可能从初始的60%下降到30%。
除谷歌外,亚马逊、微软等都有动力开发自己的AI 芯片。作为AI 的重度用户,自行开发设计芯片,可能并不比大量采购自英伟达昂贵。自行设计还可排除GPU 上不必要的功能特征,优化功耗。当然,出自差异化自身基础设施和云服务产品的初衷,这些公司不大可能出售芯片,而只会允许第三方开发者通过云端调用的方式使用。
GPU 做推断,可能大材小用。英伟达也在大力发展推断业务。自去年5 月硅谷GTC大会上宣布推出推理加速器TensorRT 以来,已有超过1200 家客户企业开始使用。TensorRT 3 适配于Volta GPU,在7ms 延迟下,可使V100 相比P100 的推理速度提高3.7 倍,并可使在V100 上优化和部署TensorFlow 模型,比其自带的推理框架,速度提高18 倍。然而,GPU 的功耗和价格,可能对很多推断工作量来说,缺乏经济性。
FPGAs 有低功耗、低延迟、定制化的优点。FPGAs 平均每瓦特的性能在图片CNN 算法推理、语音LSTM 算法推理上,比CPU 分别提高30/81 倍。英特尔的FPGA 已被微软Azure 采用,赛灵思已被亚马逊云、百度云和华为采用。新任赛灵思CEO 对数据中心业务的重视程度超过前任,预计2019 年可贡献显著增长,2020 年收入可超过3亿美元。(对FPGAs 及其与GPU 区别的详细介绍,参见《寻找AI+淘金热中的卖水人》)
可能出现整合方案。英特尔已推出了FPGAs 加CPU 的整合方案(Xeon + Altera Arria10),公司还近期宣布重新进入分立GPU 市场,不排除未来针对数据中心AI 服务器,推出GPU 加CPU 的整合方案。整合方案至少可以减少体积。
参考观研天下发布《2018年中国AI芯片行业分析报告-市场运营态势与发展前景研究》
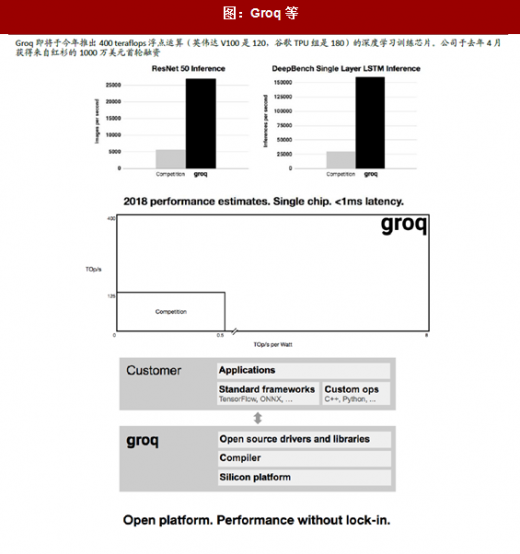
创投活跃。芯片业因其高昂的开发成本、较长的产品导入期和较高的失败率,本是VC 投资较少的领域。但AI 所可能引发的革命性变化,使AI 芯片的创业投资格外活跃。在服务器AI 芯片上,我们看到Wave Computing、Graphcore、Cerebras Systems、Groq 等已经或即将推出第一代产品。相比GPU,这些创业公司专门针对深度学习/人工智能算法训练和推理开发的xPU,可能具备更高的计算效率、能量效率和可编程性。当然,我们也预期,这些创业公司如能成功打造出被业界认可的AI 加速器,将成为大公司的收购标的。
图:科技巨头/云服务商是数据中心AI 芯片的主要推动者

图:各行业企业对人工智能的应用也在启动,或本地部署或云上调用

表:数据中心训练芯片市场规模将从2017 年的14.7 亿美元,年均增长65%至2022 年的182 亿美元

表:数据中心推断芯片市场规模将从2017 年的8400 万美元,年均增长145%至2022 年的74 亿美元

表:在云环境下训练TsnsorFlow 算法,TPU 比GPU 更优

图:对于重度使用者,自行设计开发可能比外购更合算

图:正在研发数据中心AI 芯片的创业公司包括Wave Computing…

…图:Graphcore

Graphcore 成立于2016 年,总部位于英国,其团队成员来自Altera(被英特尔收购)和Icera(被英伟达收购)。公司的产品主要是IPU(Intelligent ProcessingUnit)处理器,该处理器经过优化,可以高效的处理机器学习领域中极其复杂的高维模型。IPU 强调大规模并行运算和低精度浮点运算,与其它解决方案相比,IPU 拥有更高的计算密度以及超过100 倍的内存带宽,可以完全在内部处理机器学习模型,拥有更低的能耗与性能。IPU 产品包括IPU设备与IPU 加速器,前者旨在为云和企业数据中心服务,帮助加速AI 应用并降低成本,并将训练和推理环节提速10x 和100x;后者是一个PCle 卡,能够插入服务器中以加速机器学习应用。公司还为主流机器学习框架例如TensorFlow 和MXNet 提供无缝界面。为了支持该界面,Graphcore 推出了灵活的开源图形编程软件框架Poplar,其中包含工具、驱动及应用库,使用C++或Python 界面,允许开发人员修改和扩展库,从而更快更方便的使用IPU 系统。公司表示,其产品可以让客户在同一芯片上进行训练和推理,例如白天进行推理(算法执行),夜间利用当日获得的新数据对算法进行再训练。公司计划今年初开始向早期客户发货。公司于去年11 月获得5000 美元C 轮融资,累计融资额1.1 亿美元。
图:Cerebras Systems

图:Groq 等

资料来源:观研天下整理,转载请注明出处。(ww)
更多好文每日分享,欢迎关注公众号

【版权提示】观研报告网倡导尊重与保护知识产权。未经许可,任何人不得复制、转载、或以其他方式使用本网站的内容。如发现本站文章存在版权问题,烦请提供版权疑问、身份证明、版权证明、联系方式等发邮件至kf@chinabaogao.com,我们将及时沟通与处理。








