CPU 的介绍和分类
CPU(Central Processing Unit)中央处理器,是计算机的运算和控制核心(Control Unit),它的功能主要是解释计算机指令以及处理计算机软件中的数据。
中央处理器内部主要包括运算器(ALU,Arithmetic Logic Unit)和高速缓冲存储器(Cache)及实现它们之间联系的数据、控制及状态的总线。CPU 依靠指令来自计算和控制系统,每款 CPU 在设计时就规定了一系列与其硬件电路相配合的指令系统,从大类划分上可分为复杂指令集(CISC)和精简指令集(RISC)两种。
复杂指令集 CISC(Complex Instruction Set Computing),指令系统比较丰富,有专用指令来完成特定的功能,程序的各条指令是按顺序串行执行的,每条指令中的各个操作也是按顺序串行执行的。
复杂指令集系统的优点是控制简单,处理高级语言和特定任务能力强,缺点是结构过于复杂、指令集利用效率不高、执行速度慢。当前绝大多数 PC 和低端服务器采用的都是 CISC 架构 CPU,代表型的产品是 Intel 公司的 X86 系列。
精简指令集 RISC(Reduced Instruction Set Computing),相对于复杂指令系统,精简指令系统保留使用频率高的指令,对不常用的指令功能功能通过组合指令来完成,以此提高程序处理速度,同时 RISC 架构 CPU 采用超标量和超流水线结构,大大提升了并行处理能力。中高档服务器中普遍采用 RISC 架构的 CPU,特别是高档服务器全都采用 RISC架构的 CPU,如 PowerPC 处理器、SPARC 处理器、PA-RISC 处理器、MIPS 处理器、Alpha 处理器等。智能手机处理器需要高效率低功耗,主流的 ARM 处理器采用的也是 RISC 架构。
GPU的介绍和分类
GPU(Graphics Processing Unit)图形处理器,又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和手机平板电脑等移动设备上进行图像运算工作的微处理器。随着通用计算技术发展,GPU 的功能已经不再局限于图形处理了,在浮点运算、并行计算等高性能计算方面开始有广泛的应用。GPU 在分类上主要分为集成显卡和独立显卡。
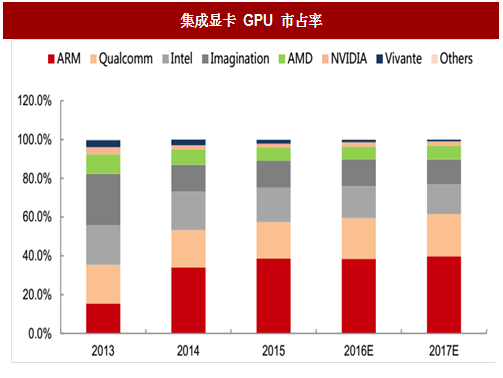
集成显卡。集成显卡是指芯片组集成了显示芯片,不用再外接显卡,具有价格低、兼容性好和升级成本低等优点。集成显卡性能一般要比中高端的独显性能差,主要原因是没有独立的显存,要占用部分内存容量作为显存,因此在某些方面影响电脑性能。集成显卡一般用在嵌入式电子、移动终端、手机射频芯片等领域,在嵌入式显卡领域,ARM 的 mali 芯片 2016 年具有接近 40%的市场占有率,其次是芯片巨头高通和 Intel。
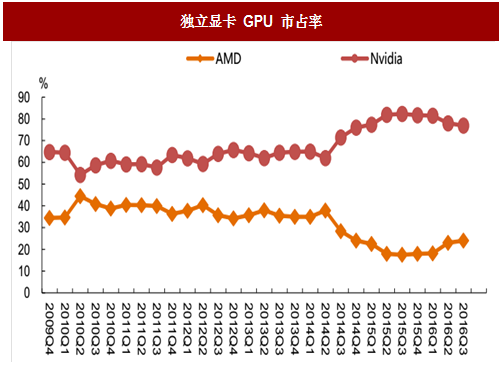
独立显卡。独立显卡没有集成到主板上,一般是插到主板相应接口上的。独立显卡最主要的优点在于本身带有独立显存,不会占用系统内存,而且独显可在电脑内部组成多显卡,拥有强大的图像处理能力。一般高性能游戏电脑都是采用独立显卡,应用于 VR/AR、人工智能等领域的高性能显卡也一定是独立显卡。在独立显卡的领域,英伟达和 AMD 二分天下,2015 年英伟达占据 80%以上的市场份额,AMD GPU 市占率不到 20%。
CPU 作为运算和控制核心在人工智能计算中占有重要基础地位
参考中国报告网发布《2017-2022年中国计算机产业现状调查及发展定位分析报告》
CPU 作为运算和控制核心,在未来高性能计算中将更多与其他专用芯片搭配使用。CPU由于要兼顾运算和控制功能,内部大量晶体管用于构建控制电路(比如分支预测等)和高速缓冲存储器(Cache),单从运算性能和效率上来说并不是计算芯片的最佳选择。由于之前人工智能高性能计算需求尚未集中出现,普通的机器学习和深度学习需求用传统 CPU 服务器也可以满足。根据 Intel 内部报告统计,2016 年服务器市场中有 7%被用于人工智能产业,其中 60%用于普通机器学习 40%用于深度学习,普通机器学习中 97%使用传统CPU 架构 1%使用 CPU+GPU 架构,深度学习中 91%使用传统 CPU 架构 7%采用CPU+GPU 架构。未来随着人工智能对计算性能和低能耗要求越来越高,以及 GPU、FPGA、 ASIC 专用芯片等产品不断成熟,CPU 在人工智能专用计算领域占比预计将越来越低,但其作为计算系统控制核心将更多的与其他专用计算芯片搭配使用。

GPU 计算能力和通用性强,软件生态完备非常适合人工智能计算
GPU 的计算能力远超 CPU。GPU 和 CPU 架构差异很大:CPU 功能模块很多,大部分晶体管主要用于构建控制电路(比如分支预测等)和高速缓冲存储器(Cache),只有少部分的晶体管可以组成各类专用电路、多条流水线,能适应复杂运算环境;GPU 构成相对简单,流处理器和显存控制器占据绝大部分功能部件,使得 GPU 拥有惊人的浮点运算能力和计算速度。现在 CPU 的技术进步逐渐慢于摩尔定律,而 GPU 的发展超过摩尔定律。 GPU 还有一大优势是可以并行处理多个任务,其大规模并行计算能力用于人工智能神经网络之间的连接非常适合。深度学习算法通常需要海量计算来处理数据(图像、语音、文本等)和提取数据对象特征并进行反复训练,传统的 CPU 集群需要数周才能计算出拥有 1 亿节点的神经网络级联,而一个 GPU 集群在一天内就可以完成,速度优势明显。

GPU 的并行数据处理流程大幅提高运算能力。
GPU 从 CPU 处得到数据处理的指令,把大规模、无结构化的数据分解成很多独立的部分然后分配给各个流处理器集群。每个流处理器集群再次把数据分解,分配给调度器所控制的多个计算核心同时执行数据的计算和处理。
如果一个核心的计算算作一个线程,那么 GPU 中多个线程同时进行数据的处理。尽管每个线程/Core 的计算性能、效率与 CPU 中的 Core 相比低了不少,但是当所有线程都并行计算,那么累加之后它的计算能力又远远高于 CPU。
对于基于神经网络的深度学习来说,它硬件计算精度要求远远没有对其并行处理能力的要求来的迫切,而这种并行计算能力转化为对于硬件的要求就是尽可能大的逻辑单元规模,通常我们使用每秒钟进行的浮点运算(Flops/s)来量化的参数,对于单精度浮点运算,GPU 的执行效率远远高于 CPU。
GPU 的共享内存结构可提高线程间通信速度。在 NVIDIA 披露的 GPU 性能参数中,每个流处理器集群末端设有共享内存。相比于 CPU 每次操作数据都要返回内存再进行调用, GPU 线程之间的数据通讯不需要访问全局内存,而在共享内存中就可以直接访问。这种设置的带来的好处就是线程间通讯速度的提高。
GPU 的高速全局内存可进一步提升运算速度。目前 GPU 上普遍采用 GDDR5 的显存颗粒,不仅具有更高的工作频率,从而带来更快的数据读取/写入速度,而且具有更大的显存带宽。我们认为在数据处理中,速度往往最终取决于处理器从内存中提取数据以及流入和通过处理器要花多少时间。
而在传统的 CPU 构架中,尽管有高速缓存(Cache)的存在,但是由于其容量较小,大量的数据只能存放在内存(RAM)中。进行数据处理时,数据要从内存中读取然后在 CPU 中运算最后返回内存中。由于构架的原因,二者之间的通信带宽通常在 60GB/s 左右徘徊。与之相比,大显存带宽的 GPU 具有更大的数据吞吐量。在大规模深度神经网络的训练中,必然带来更大的优势。
GPU 拥有完备的人工智能计算软件生态。越来越多的深度学习标准库支持基于 GPU 的深度学习加速,通俗点描述就是深度学习的编程框架会自动根据 GPU 所具有的线程/Core数,去自动分配数据的处理策略,从而达到优化深度学习的时间。
CPU(Central Processing Unit)中央处理器,是计算机的运算和控制核心(Control Unit),它的功能主要是解释计算机指令以及处理计算机软件中的数据。
中央处理器内部主要包括运算器(ALU,Arithmetic Logic Unit)和高速缓冲存储器(Cache)及实现它们之间联系的数据、控制及状态的总线。CPU 依靠指令来自计算和控制系统,每款 CPU 在设计时就规定了一系列与其硬件电路相配合的指令系统,从大类划分上可分为复杂指令集(CISC)和精简指令集(RISC)两种。
复杂指令集 CISC(Complex Instruction Set Computing),指令系统比较丰富,有专用指令来完成特定的功能,程序的各条指令是按顺序串行执行的,每条指令中的各个操作也是按顺序串行执行的。
复杂指令集系统的优点是控制简单,处理高级语言和特定任务能力强,缺点是结构过于复杂、指令集利用效率不高、执行速度慢。当前绝大多数 PC 和低端服务器采用的都是 CISC 架构 CPU,代表型的产品是 Intel 公司的 X86 系列。
精简指令集 RISC(Reduced Instruction Set Computing),相对于复杂指令系统,精简指令系统保留使用频率高的指令,对不常用的指令功能功能通过组合指令来完成,以此提高程序处理速度,同时 RISC 架构 CPU 采用超标量和超流水线结构,大大提升了并行处理能力。中高档服务器中普遍采用 RISC 架构的 CPU,特别是高档服务器全都采用 RISC架构的 CPU,如 PowerPC 处理器、SPARC 处理器、PA-RISC 处理器、MIPS 处理器、Alpha 处理器等。智能手机处理器需要高效率低功耗,主流的 ARM 处理器采用的也是 RISC 架构。
GPU的介绍和分类
GPU(Graphics Processing Unit)图形处理器,又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和手机平板电脑等移动设备上进行图像运算工作的微处理器。随着通用计算技术发展,GPU 的功能已经不再局限于图形处理了,在浮点运算、并行计算等高性能计算方面开始有广泛的应用。GPU 在分类上主要分为集成显卡和独立显卡。
集成显卡。集成显卡是指芯片组集成了显示芯片,不用再外接显卡,具有价格低、兼容性好和升级成本低等优点。集成显卡性能一般要比中高端的独显性能差,主要原因是没有独立的显存,要占用部分内存容量作为显存,因此在某些方面影响电脑性能。集成显卡一般用在嵌入式电子、移动终端、手机射频芯片等领域,在嵌入式显卡领域,ARM 的 mali 芯片 2016 年具有接近 40%的市场占有率,其次是芯片巨头高通和 Intel。

图:集成显卡 GPU 市占率
独立显卡。独立显卡没有集成到主板上,一般是插到主板相应接口上的。独立显卡最主要的优点在于本身带有独立显存,不会占用系统内存,而且独显可在电脑内部组成多显卡,拥有强大的图像处理能力。一般高性能游戏电脑都是采用独立显卡,应用于 VR/AR、人工智能等领域的高性能显卡也一定是独立显卡。在独立显卡的领域,英伟达和 AMD 二分天下,2015 年英伟达占据 80%以上的市场份额,AMD GPU 市占率不到 20%。

图:独立显卡 GPU 市占率
CPU 作为运算和控制核心在人工智能计算中占有重要基础地位
参考中国报告网发布《2017-2022年中国计算机产业现状调查及发展定位分析报告》
CPU 作为运算和控制核心,在未来高性能计算中将更多与其他专用芯片搭配使用。CPU由于要兼顾运算和控制功能,内部大量晶体管用于构建控制电路(比如分支预测等)和高速缓冲存储器(Cache),单从运算性能和效率上来说并不是计算芯片的最佳选择。由于之前人工智能高性能计算需求尚未集中出现,普通的机器学习和深度学习需求用传统 CPU 服务器也可以满足。根据 Intel 内部报告统计,2016 年服务器市场中有 7%被用于人工智能产业,其中 60%用于普通机器学习 40%用于深度学习,普通机器学习中 97%使用传统CPU 架构 1%使用 CPU+GPU 架构,深度学习中 91%使用传统 CPU 架构 7%采用CPU+GPU 架构。未来随着人工智能对计算性能和低能耗要求越来越高,以及 GPU、FPGA、 ASIC 专用芯片等产品不断成熟,CPU 在人工智能专用计算领域占比预计将越来越低,但其作为计算系统控制核心将更多的与其他专用计算芯片搭配使用。

图:2016 年全球数据中心 AI 应用统计
GPU 计算能力和通用性强,软件生态完备非常适合人工智能计算
GPU 的计算能力远超 CPU。GPU 和 CPU 架构差异很大:CPU 功能模块很多,大部分晶体管主要用于构建控制电路(比如分支预测等)和高速缓冲存储器(Cache),只有少部分的晶体管可以组成各类专用电路、多条流水线,能适应复杂运算环境;GPU 构成相对简单,流处理器和显存控制器占据绝大部分功能部件,使得 GPU 拥有惊人的浮点运算能力和计算速度。现在 CPU 的技术进步逐渐慢于摩尔定律,而 GPU 的发展超过摩尔定律。 GPU 还有一大优势是可以并行处理多个任务,其大规模并行计算能力用于人工智能神经网络之间的连接非常适合。深度学习算法通常需要海量计算来处理数据(图像、语音、文本等)和提取数据对象特征并进行反复训练,传统的 CPU 集群需要数周才能计算出拥有 1 亿节点的神经网络级联,而一个 GPU 集群在一天内就可以完成,速度优势明显。

图:CPU 和 GPU 微结构对比
GPU 的并行数据处理流程大幅提高运算能力。
GPU 从 CPU 处得到数据处理的指令,把大规模、无结构化的数据分解成很多独立的部分然后分配给各个流处理器集群。每个流处理器集群再次把数据分解,分配给调度器所控制的多个计算核心同时执行数据的计算和处理。
如果一个核心的计算算作一个线程,那么 GPU 中多个线程同时进行数据的处理。尽管每个线程/Core 的计算性能、效率与 CPU 中的 Core 相比低了不少,但是当所有线程都并行计算,那么累加之后它的计算能力又远远高于 CPU。
对于基于神经网络的深度学习来说,它硬件计算精度要求远远没有对其并行处理能力的要求来的迫切,而这种并行计算能力转化为对于硬件的要求就是尽可能大的逻辑单元规模,通常我们使用每秒钟进行的浮点运算(Flops/s)来量化的参数,对于单精度浮点运算,GPU 的执行效率远远高于 CPU。
GPU 的共享内存结构可提高线程间通信速度。在 NVIDIA 披露的 GPU 性能参数中,每个流处理器集群末端设有共享内存。相比于 CPU 每次操作数据都要返回内存再进行调用, GPU 线程之间的数据通讯不需要访问全局内存,而在共享内存中就可以直接访问。这种设置的带来的好处就是线程间通讯速度的提高。
GPU 的高速全局内存可进一步提升运算速度。目前 GPU 上普遍采用 GDDR5 的显存颗粒,不仅具有更高的工作频率,从而带来更快的数据读取/写入速度,而且具有更大的显存带宽。我们认为在数据处理中,速度往往最终取决于处理器从内存中提取数据以及流入和通过处理器要花多少时间。
而在传统的 CPU 构架中,尽管有高速缓存(Cache)的存在,但是由于其容量较小,大量的数据只能存放在内存(RAM)中。进行数据处理时,数据要从内存中读取然后在 CPU 中运算最后返回内存中。由于构架的原因,二者之间的通信带宽通常在 60GB/s 左右徘徊。与之相比,大显存带宽的 GPU 具有更大的数据吞吐量。在大规模深度神经网络的训练中,必然带来更大的优势。
GPU 拥有完备的人工智能计算软件生态。越来越多的深度学习标准库支持基于 GPU 的深度学习加速,通俗点描述就是深度学习的编程框架会自动根据 GPU 所具有的线程/Core数,去自动分配数据的处理策略,从而达到优化深度学习的时间。
资料来源:中国报告网整理,转载请注明出处(GQ)
更多好文每日分享,欢迎关注公众号

【版权提示】观研报告网倡导尊重与保护知识产权。未经许可,任何人不得复制、转载、或以其他方式使用本网站的内容。如发现本站文章存在版权问题,烦请提供版权疑问、身份证明、版权证明、联系方式等发邮件至kf@chinabaogao.com,我们将及时沟通与处理。








