参考中国报告网发布《2017-2021年中国人工智能市场发展现状及投资方向研究报告》
深度学习推动神经网络算法发展步入爆发期
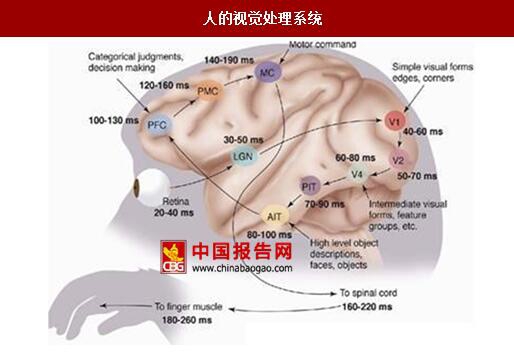
1981年诺贝尔医学奖获得者的研究成果显示,人的视觉系统信息处理是分级的。视觉信号通过视网膜触发,经过相对低级的V1区提取边缘特征,到V2区形成基本形状或目标的局部,再到相对高层的V4区形成整个目标(如判定为一张人脸),进而到更高层的PFC(前额叶皮层)进行分类判断等。值得注意的是,对于人脑来说,高层的特征是低层特征的组合,从低层到高层的特征表达越来越抽象和概念化。
与人类智能相对应,科学界一直致力于模仿人类的智能思维达到甚至超越人类的能力。1943年,心理学家WarrenMcculloch和数理逻辑学家WalterPitts在合作的论文中首次提出并给出了人工神经网络的概念及人工神神经元的数学模型,从而开创了人类神经网络研究的时代。1969年,美国数学家及人工智能先驱Minsky在其著作中证明了感知器本质上是一种线性模型,只能处理线性分类问题,就连最简单的XOR问题都无法正确分类。这等于直接宣判了感知器的死刑,神经网络的研究也陷入了近20年的停滞,陷入第一次低谷。
1986年Hinton发明了适用于多层感知器(MLP)的BP算法,并采用Sigmoid进行非线性映射,有效解决了非线性分类和学习的问题。该方法引起了神经网络的第二次热潮。1991年,BP算法被指出存在梯度消失问题,因此无法对前层进行有效的学习,由于1989年以后没有特别突出的方法被提出,且NN一直缺少相应的严格的数学理论支持,热潮逐渐褪去,该发现对此时的NN发展更是雪上加霜,自此神经网络步入第二次低谷期。
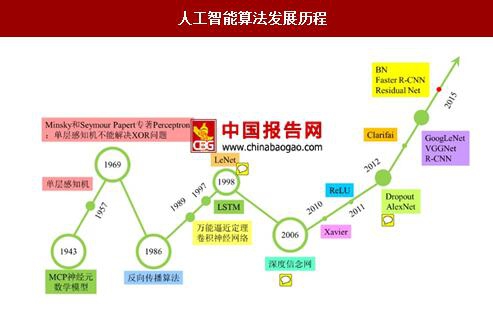
直至2006年,加拿大多伦多大学教授GeoffreyHinton对深度学习的提出以及模型训练方法的改进打破了BP神经网络发展的瓶颈。Hinton在世界顶级学术期刊《科学》上的一篇论文中提出了两个观点
(1)多层人工神经网络模型有很强的特征学习能力,深度学习模型学习得到的特征数据对原始数据有更本质的代表性,这将大大便于分类和可视化问题;
(2)对于深度神经网络很难训练达到最优的问题,可以采用逐层训练方法解决。将上层训练好的结果作为下层训练过程中的初始化参数。
在这一文献中深度模型的训练过程中逐层初始化采用无监督学习方式。深度学习模型的提出将神经网络第三次推向快速发展期。2012年,Hinton课题组为了证明深度学习的潜力,首次参加ImageNet图像识别比赛,其通过构建的CNN网络AlexNet一举夺得冠军,且碾压第二名(SVM方法)的分类性能,CNN吸引到了众多研究者的注意。
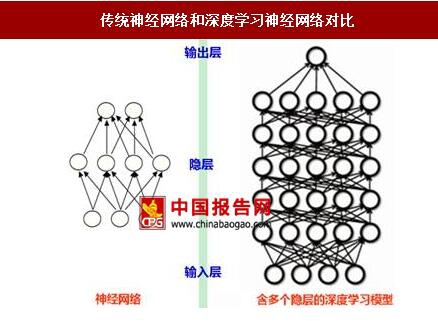
自此以后,多种基于深度学习框架的算法模型被提出和应用,算法的发展进入爆发期。深度学习是通过大量的简单神经元组成,每层的神经元接收更低层神经元的输入,通过输入与输出的非线性关系将低层特征组合成更高层的抽象表示,直至完成输出。
传统机器学习为了进行某种模式的识别,通常的做法首先是以某种方式,提取这个模式中的特征。在传统机器模型中,良好的特征表达,对最终算法的准确性起了非常关键的作用,且识别系统的计算和测试工作耗时主要集中在特征提取部分,特征的提取方式有时候是人工设计或指定的,主要依靠人工提取。
与传统机器学习不同的是,深度学习提出了一种让计算机自动学习出模式特征的方法,并将特征学习融入到了建立模型的过程中,从而减少了人为设计特征造成的不完备性。而目前以深度学习为核心的某些机器学习应用,在满足特定条件的应用场景下,已经达到了超越现有算法的识别或分类性能。
深度学习直接尝试解决抽象认知的难题,并取得了突破性的进展。深度学习的提出、应用与发展,无论从学术界还是从产业界来说均将人工智能带上了一个新的台阶,将人工智能产业带入了一个全新的发展阶段。
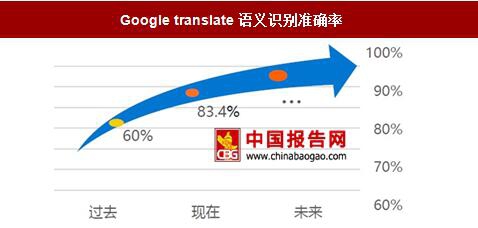
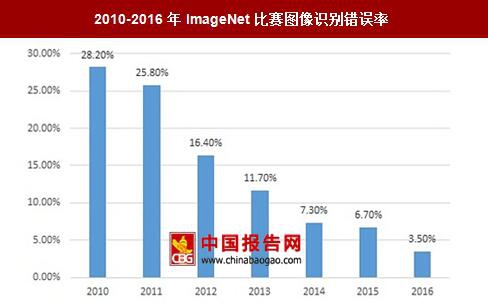
深度学习的应用使得语义识别、图像识别的准确率大幅提升。以ImageNet比赛为例,图像识别的错误率由2010年的28.2%降低到2016年的3.5%。而Google的语义识别项目Googletranslate在应用深度学习后准确率从60%提升到了目前的83.4%。
计算成本指数级下降,芯片加速发展为深度学习奠定计算基础
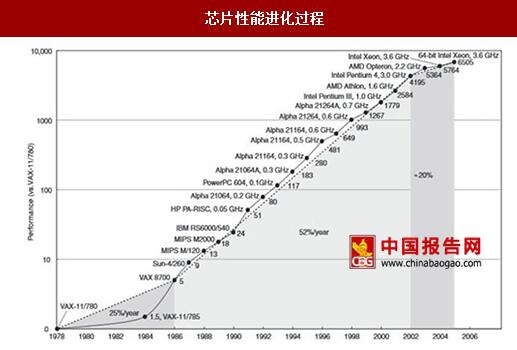
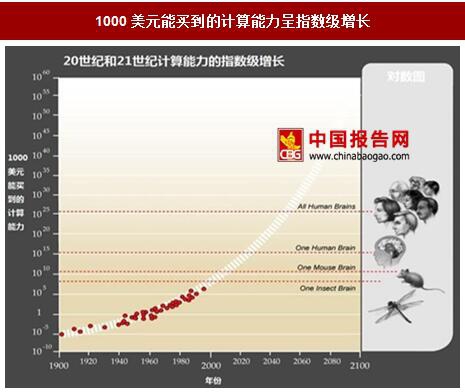
人工智能领域的发展与芯片性能的进步是分不开的。人工智能之所以在90年代以前有一段很大的发展空白的一个主要原因是算力不足。90年代人工智能取得的突破很大程度是由于半导体芯片性能的增加。从芯片性能进化史中可以看出,90年代是芯片性能高速发展取得突破的时代。从1978-1986年,芯片性能几乎以每年25%的速度增长;从80年代中期到2000年芯片进入高速发展期,性能年均增长率更是达到52%。所以芯片性能的提升极大的促进人工智能科技的发展。未来科学家Kurzweil认为当1000美元能买到人脑级别的1亿亿运算能力的时候,强人工智能可能成为生活中的一部分。
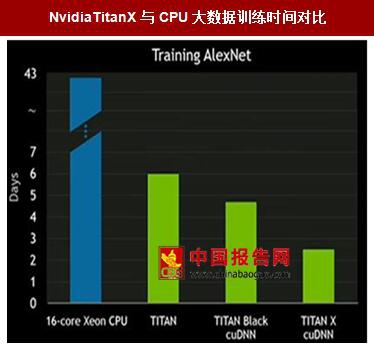
在现代主流DNNs架构中(比如AlexNEt,VGG),很大程度上依赖于对于32位浮点数据的大规模矩阵乘法运算(GEEM)。由于GPU的架构有着很好地并行计算能力,而且配备了很多浮点运算模块与高带宽片上存储器,所以深度学习的算法特别特别适合GPU。在下图可以看出,GPU在大数据训练方面的时间只需要传统CPU十分之一的时间。
然而下一代DNNs的发展趋势之一是需要更多层次计算结构与相对更紧凑的数据模型。GPU在架构配置方面不够灵活,例如对于不规则并行运算的处理,这就为FPGA提供了用武之地,而且单位功耗的运算能力上,FPGA占有很大优势。
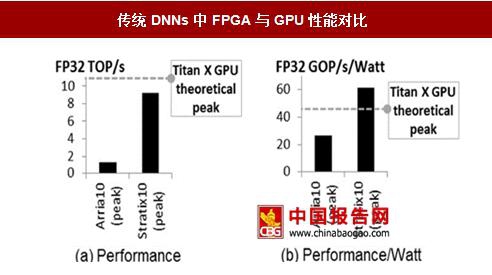
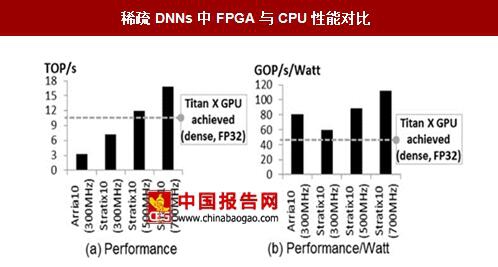
传统DNNs中,Intel最先进的FPGAstratix10性能与英伟达TitanXGPU有一定差距,每秒浮点运算速度只能达到GPU的80%,但是单位功耗性能上,FPGA有优势,每瓦特浮点运算速度超过GPU50%。而下一代DNNs的发展趋势是在稀疏网络中进行,修剪(Pruning)型矩阵是新的一种流行架构,可以让DNN的权重降低而不损失精确度,而在稀疏深度学习网络应用中(SparseDNNs),FPGA的优势逐渐体现,FPGA在性能和单位功耗的性能均超过了CPU。
所以,不同芯片类型适用于不同的应用场景。目前给人工智能芯片下结论还为时过早。随着未来人工智能架构的发展,随时有可能出现新的软件架构,而也会出现新的芯片建构与之相适应。
数据量爆炸,为深度学习奠定数据基础
人脑认知世界的过程是一个不断学习、吸收理解与自我完善的过程,通过对历史经验的总结整理最终实现大脑意识的强化与进阶,深度学习方法与之类似。它是利用机器算法模拟人脑对历史知识的学习、吸收、理解,并最终能够掌握运用的训练过程。由此可见,算法是人工智能技术的核心,而数据量人工智能得以实现的保障,二者不可或缺。
算法是计算机归纳所训练数据集特征的方法,优秀的算法可以实现训练数据集对象特征的准确的收集。就目前可应用的人工智能算法而言,需要大量样本的归纳总结进而得出自己的识别逻辑,这样数据集的丰富性和规模对算法训练的结果非常重要。通常图像识别的算法训练,数据量规模应该是在百万级别。

近年来,随着移动设备渗透率的逐步提升,全球数据量加速爆发。根据监测统计,2011年全球数据总量已经达到0.7ZB(1ZB等于1万亿GB,0.7ZB也就相当于7亿个1TB的移动硬盘),而这个数值还在以每两年翻一番的速度增长。
2015年全球的数据总量为8.6ZB,目前全球数据的增长速度在每年40%左右,预计到2020年全球全球的数据总量将达到40ZB。在2016年贵阳召开的中国大数据产业峰会上,国家发展和改革委员会副主任林念修称,到2020年中国的数据总量将会超过8000亿,占全球数据总量的比例达到20%,届时中国将成为世界第一数据资源大国和全球的数据中心。
根据36kr的数据显示,随着测试字符数量逐步增长,算法模型的准确率也在逐步提升,可见数据量是支撑模型训练提升准确率的重要资源,在人工智能发展中必不可少。
近年来深度学习成功的关键是有足够多的数据对人工智能系统进行训练,随着移动互联网的爆发,数据量指数级的增长,这都为利用大数据进行深度学习提供了可能。因此,在DT时代,大数据在知识解析、机器智能与人类智能协调工作及智能分析系统中将会扮演要角色,在大数据的支撑下,人工智能应用也将变的更加广泛,大数据将支撑人工智能产业爆发。
深度学习推动神经网络算法发展步入爆发期
1981年诺贝尔医学奖获得者的研究成果显示,人的视觉系统信息处理是分级的。视觉信号通过视网膜触发,经过相对低级的V1区提取边缘特征,到V2区形成基本形状或目标的局部,再到相对高层的V4区形成整个目标(如判定为一张人脸),进而到更高层的PFC(前额叶皮层)进行分类判断等。值得注意的是,对于人脑来说,高层的特征是低层特征的组合,从低层到高层的特征表达越来越抽象和概念化。
人的视觉处理系统

资料来源:中国报告网整理
与人类智能相对应,科学界一直致力于模仿人类的智能思维达到甚至超越人类的能力。1943年,心理学家WarrenMcculloch和数理逻辑学家WalterPitts在合作的论文中首次提出并给出了人工神经网络的概念及人工神神经元的数学模型,从而开创了人类神经网络研究的时代。1969年,美国数学家及人工智能先驱Minsky在其著作中证明了感知器本质上是一种线性模型,只能处理线性分类问题,就连最简单的XOR问题都无法正确分类。这等于直接宣判了感知器的死刑,神经网络的研究也陷入了近20年的停滞,陷入第一次低谷。
1986年Hinton发明了适用于多层感知器(MLP)的BP算法,并采用Sigmoid进行非线性映射,有效解决了非线性分类和学习的问题。该方法引起了神经网络的第二次热潮。1991年,BP算法被指出存在梯度消失问题,因此无法对前层进行有效的学习,由于1989年以后没有特别突出的方法被提出,且NN一直缺少相应的严格的数学理论支持,热潮逐渐褪去,该发现对此时的NN发展更是雪上加霜,自此神经网络步入第二次低谷期。
人工智能算法发展历程

资料来源:中国报告网整理
直至2006年,加拿大多伦多大学教授GeoffreyHinton对深度学习的提出以及模型训练方法的改进打破了BP神经网络发展的瓶颈。Hinton在世界顶级学术期刊《科学》上的一篇论文中提出了两个观点
(1)多层人工神经网络模型有很强的特征学习能力,深度学习模型学习得到的特征数据对原始数据有更本质的代表性,这将大大便于分类和可视化问题;
(2)对于深度神经网络很难训练达到最优的问题,可以采用逐层训练方法解决。将上层训练好的结果作为下层训练过程中的初始化参数。
在这一文献中深度模型的训练过程中逐层初始化采用无监督学习方式。深度学习模型的提出将神经网络第三次推向快速发展期。2012年,Hinton课题组为了证明深度学习的潜力,首次参加ImageNet图像识别比赛,其通过构建的CNN网络AlexNet一举夺得冠军,且碾压第二名(SVM方法)的分类性能,CNN吸引到了众多研究者的注意。
自此以后,多种基于深度学习框架的算法模型被提出和应用,算法的发展进入爆发期。深度学习是通过大量的简单神经元组成,每层的神经元接收更低层神经元的输入,通过输入与输出的非线性关系将低层特征组合成更高层的抽象表示,直至完成输出。
传统神经网络和深度学习神经网络对比

资料来源:中国报告网整理
传统机器学习为了进行某种模式的识别,通常的做法首先是以某种方式,提取这个模式中的特征。在传统机器模型中,良好的特征表达,对最终算法的准确性起了非常关键的作用,且识别系统的计算和测试工作耗时主要集中在特征提取部分,特征的提取方式有时候是人工设计或指定的,主要依靠人工提取。
与传统机器学习不同的是,深度学习提出了一种让计算机自动学习出模式特征的方法,并将特征学习融入到了建立模型的过程中,从而减少了人为设计特征造成的不完备性。而目前以深度学习为核心的某些机器学习应用,在满足特定条件的应用场景下,已经达到了超越现有算法的识别或分类性能。
深度学习直接尝试解决抽象认知的难题,并取得了突破性的进展。深度学习的提出、应用与发展,无论从学术界还是从产业界来说均将人工智能带上了一个新的台阶,将人工智能产业带入了一个全新的发展阶段。
Google translate语义识别准确率

数据来源:中国报告网整理
2010-2016年ImageNet比赛图像识别错误率

数据来源:中国报告网整理
深度学习的应用使得语义识别、图像识别的准确率大幅提升。以ImageNet比赛为例,图像识别的错误率由2010年的28.2%降低到2016年的3.5%。而Google的语义识别项目Googletranslate在应用深度学习后准确率从60%提升到了目前的83.4%。
计算成本指数级下降,芯片加速发展为深度学习奠定计算基础
人工智能领域的发展与芯片性能的进步是分不开的。人工智能之所以在90年代以前有一段很大的发展空白的一个主要原因是算力不足。90年代人工智能取得的突破很大程度是由于半导体芯片性能的增加。从芯片性能进化史中可以看出,90年代是芯片性能高速发展取得突破的时代。从1978-1986年,芯片性能几乎以每年25%的速度增长;从80年代中期到2000年芯片进入高速发展期,性能年均增长率更是达到52%。所以芯片性能的提升极大的促进人工智能科技的发展。未来科学家Kurzweil认为当1000美元能买到人脑级别的1亿亿运算能力的时候,强人工智能可能成为生活中的一部分。
芯片性能进化过程

资料来源:中国报告网整理
1000美元能买到的计算能力呈指数级增长

资料来源:中国报告网整理
在现代主流DNNs架构中(比如AlexNEt,VGG),很大程度上依赖于对于32位浮点数据的大规模矩阵乘法运算(GEEM)。由于GPU的架构有着很好地并行计算能力,而且配备了很多浮点运算模块与高带宽片上存储器,所以深度学习的算法特别特别适合GPU。在下图可以看出,GPU在大数据训练方面的时间只需要传统CPU十分之一的时间。
NvidiaTitanX与CPU大数据训练时间对比

数据来源:中国报告网整理
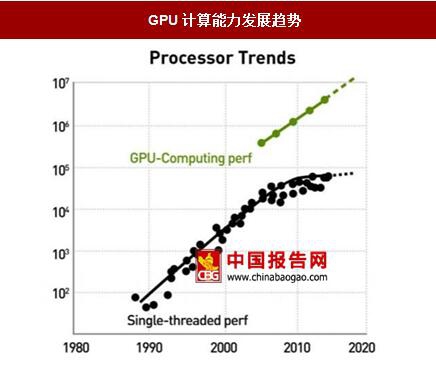
GPU计算能力发展趋势

数据来源:中国报告网整理
然而下一代DNNs的发展趋势之一是需要更多层次计算结构与相对更紧凑的数据模型。GPU在架构配置方面不够灵活,例如对于不规则并行运算的处理,这就为FPGA提供了用武之地,而且单位功耗的运算能力上,FPGA占有很大优势。
传统DNNs中,Intel最先进的FPGAstratix10性能与英伟达TitanXGPU有一定差距,每秒浮点运算速度只能达到GPU的80%,但是单位功耗性能上,FPGA有优势,每瓦特浮点运算速度超过GPU50%。而下一代DNNs的发展趋势是在稀疏网络中进行,修剪(Pruning)型矩阵是新的一种流行架构,可以让DNN的权重降低而不损失精确度,而在稀疏深度学习网络应用中(SparseDNNs),FPGA的优势逐渐体现,FPGA在性能和单位功耗的性能均超过了CPU。
传统DNNs中FPGA与GPU性能对比

数据来源:中国报告网整理
稀疏DNNs中FPGA与CPU性能对比

数据来源:中国报告网整理
所以,不同芯片类型适用于不同的应用场景。目前给人工智能芯片下结论还为时过早。随着未来人工智能架构的发展,随时有可能出现新的软件架构,而也会出现新的芯片建构与之相适应。
数据量爆炸,为深度学习奠定数据基础
人脑认知世界的过程是一个不断学习、吸收理解与自我完善的过程,通过对历史经验的总结整理最终实现大脑意识的强化与进阶,深度学习方法与之类似。它是利用机器算法模拟人脑对历史知识的学习、吸收、理解,并最终能够掌握运用的训练过程。由此可见,算法是人工智能技术的核心,而数据量人工智能得以实现的保障,二者不可或缺。
算法是计算机归纳所训练数据集特征的方法,优秀的算法可以实现训练数据集对象特征的准确的收集。就目前可应用的人工智能算法而言,需要大量样本的归纳总结进而得出自己的识别逻辑,这样数据集的丰富性和规模对算法训练的结果非常重要。通常图像识别的算法训练,数据量规模应该是在百万级别。
大数据是人工智能发展的保障

资料来源:中国报告网整理
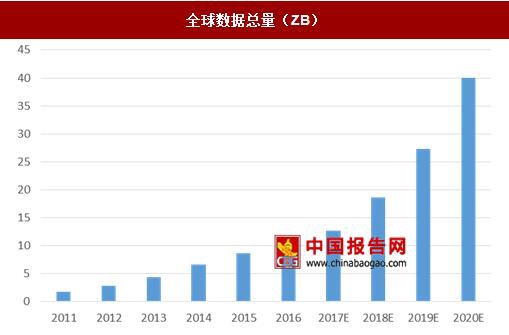
近年来,随着移动设备渗透率的逐步提升,全球数据量加速爆发。根据监测统计,2011年全球数据总量已经达到0.7ZB(1ZB等于1万亿GB,0.7ZB也就相当于7亿个1TB的移动硬盘),而这个数值还在以每两年翻一番的速度增长。
2015年全球的数据总量为8.6ZB,目前全球数据的增长速度在每年40%左右,预计到2020年全球全球的数据总量将达到40ZB。在2016年贵阳召开的中国大数据产业峰会上,国家发展和改革委员会副主任林念修称,到2020年中国的数据总量将会超过8000亿,占全球数据总量的比例达到20%,届时中国将成为世界第一数据资源大国和全球的数据中心。
全球数据总量(ZB)

数据来源:中国报告网整理
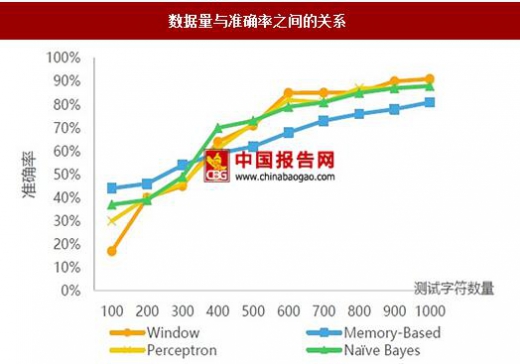
根据36kr的数据显示,随着测试字符数量逐步增长,算法模型的准确率也在逐步提升,可见数据量是支撑模型训练提升准确率的重要资源,在人工智能发展中必不可少。
数据量与准确率之间的关系

数据来源:中国报告网整理
近年来深度学习成功的关键是有足够多的数据对人工智能系统进行训练,随着移动互联网的爆发,数据量指数级的增长,这都为利用大数据进行深度学习提供了可能。因此,在DT时代,大数据在知识解析、机器智能与人类智能协调工作及智能分析系统中将会扮演要角色,在大数据的支撑下,人工智能应用也将变的更加广泛,大数据将支撑人工智能产业爆发。
资料来源:中国报告网整理,转载请注明出处(ZQ)
更多好文每日分享,欢迎关注公众号

【版权提示】观研报告网倡导尊重与保护知识产权。未经许可,任何人不得复制、转载、或以其他方式使用本网站的内容。如发现本站文章存在版权问题,烦请提供版权疑问、身份证明、版权证明、联系方式等发邮件至kf@chinabaogao.com,我们将及时沟通与处理。







