参考中国报告网发布《2017-2022年中国计算机产业现状调查及发展定位分析报告》
计算机“睁眼看世界”
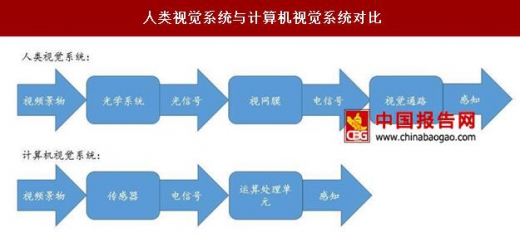
计算机视觉(Computer Vision, CV)是一门研究如何让计算机实现人类视觉系统功能的学科。人类的视觉系统主要分为眼球作用区和大脑作用区。其中眼球作用区负责将视频景物转换为大脑中的电信号,而大脑作用区则将电信号进一步转变为感知。通过以成像设备和系统替代视觉器官,并以计算机替代大脑完成视觉输入的理解和处理,CV 技术能够完成对人类视觉系统的模拟,从而实现适应、理解外界环境和控制自身运动等复杂的智能功能。
作为人工智能的重要分支之一,计算机视觉与语音识别、语言识别等技术一同构成了人工智能的感知基础。它让计算机能够“睁眼看世界”。斯坦福大学教授李飞飞将这种“看”的能力称作“计算机科学领域最前沿的、具有革命性潜力的科技”。作为人的感官的延伸,计算机视觉将被广泛应用于图像识别、人脸检测、人脸识别等方面,并逐步渗透到无人驾驶、安防、机器人、智能家居等众多领域中。可以预见,在不久的将来,计算机视觉技术将会成为许多行业发展的新动力。
尽管计算机视觉从诞生至今已经历了 50 余年的发展,该领域依然存在一些有待解决的问题。例如如何高效准确地识别目标、如何有效地构造易于实现的识别算法、如何解决实时性和稳定性问题等。这些问题也将成为计算机视觉企业的发展机遇。现在已有部分优质企业在应用方面对这些问题给出了一些解决方案。展望计算机视觉技术的未来,图像特征选择、动态性能提升等方面将会成为重点的研究方向。
诞生——来自人工智能之父的 CV 元年
1966 年被称作计算机视觉元年。尽管在此之前的 20 世纪 50 年代中,学者们已经将计算机视觉的有关技术作为统计模式识别部分内容进行了研究,但研究的内容主要集中在光学字符、显微图谱、航空图片等二维图像的分析和研究中,并且计算机视觉在此时尚未成成为一门独立的学科。在 1966 年的夏天,著名的人工智能学者马文明斯基(Marvin Lee Minsky)要求其学生通过编程让计算机告诉使用者摄像头所拍摄的内容。这一任务触及到了计算机视觉的本质之一,也标志着计算机视觉的诞生。

Larry Roberts 发表了计算机视觉领域的第一篇博士论文《Machine Perception of Three-Dimensional Solids》。Roberts 将现实世界简化为由简单的三维结构所组成的“积木世界”,并且使用计算机从“积木世界”中提取出了立方体、棱柱等多种三维结构。此外,Roberts 还对物体的形状和空间关系做出了描述。对“积木世界”的研究是计算机视觉早期的重要尝试。它使人们相信,对简单的“积木世界”的理解能够推广到更复杂的现实世界中,并最终彻底实现人类视觉系统的完全替代。
繁荣——始于理论框架的建立
随后计算机视觉进入了蓬勃发展的时代。B. K. P. Horn 教授于 20 世纪 70 年代中期在 MIT 的人工智能实验室正式开设了“计算机视觉”课程。这成为了计算机视觉史上的标志性事件之一。后来人工智能实验室的 David Marr 教授提出了著名的计算视觉理论。该理论认为人类视觉的主要功能是复原三维场景的可见几何表面,即三维重建问题,并且这种从二维图像到三维几何结构的复原过程可以通过计算完成。理论强调从不同阶段去研究时间信息处理的问题。这一理论至今仍旧是计算机视觉研究的基本框架。

20 世纪 80 年代后,计算机视觉技术又迈上了一个新的台阶。著名的卷积神经网络的实现在此期间诞生。卷积神经网络的理论基础是生物视觉中的“局部感受野”概念。生物在利用视觉识别物体的过程中并非显式地从图像中提取特征,而是通过一个自组织的深层网络结构逐层地将前一层信息抽象化。每一个视觉神经元都不感知图像的整体而只感受图像的局部信息。各个神经元感知的局部特征在神经网络的更高层级中综合时,生物就能够感知到图像的全局信息。图像局部感知能够保证图像发生平移或形变时图像的关键特征依然可以准确地被提取。
除了实现卷积神经网络外,主动视觉、目的视觉、重建理论、基于学习的视觉等重要的计算机视觉理论体系均在随后诞生。各类新方法和新理论的出现为计算机视觉带来了前所未有的繁荣。90 年代起,各类统计学习方法开始逐渐流行。统计学习通过统计方法提取了物体的局部特征。这些局部特征不同于形状、纹理等全局特征,不会犹豫平移或视角的改变而生剧烈的变化,因此具备了一定的特征旋转和平移不变性。基于局部特征,人们可以建立不同物品的局部特征集,从而实现类似物品的检索。图像搜索等技术正是因此得以发展。
进入 21 世纪后,机器学习开始大行其道。“机器学习”一词源自 IBM 的一篇论文,指利用计算机实现或模仿人类的学习行为。机器学习技术不同于先前使用的方法。它无需人为设计和提取特征,而是通过特定的算法从大量的样本中自动归纳学习。机器学习的应用需要大量的数据样本来支撑,而 2000 年以来的互联网技术的飞速发展为机器学习技术提供了所需的海量数据。例如,著名的 ImageNet 数据集包含了 2 万多个类别供 1400 万张图片。此数据集是世界上最大的图像识别数据库,计算机视觉研究人员将其作为重要的数据来源之一,开发人员不约而同地将模型在 ImageNet 上的识别准确率作为比较基准。研究者们在该数据集训练了 AlexNet、GoogleNet 等著名的模型,并且不断刷新着物体识别的准确率。
在 2006 年之前,计算机视觉中所使用的模式识别方法主要是机器学习中的浅层学习技术,如支持向量机、决策树等。这些方法存在特征提取能力不足、容易出现过拟合等问题。2006 年,Hinton 等人提出了深度臵信网络模型(DBN)。DBN 是深度学习领域的第一个模型。它通过将多个受限波尔茨曼机(RBM)堆叠成为一个深度网络结构,获得了浅层模型难以比拟的高层次抽象特征提取能力,从而具备了更加优越的性能。此模型通过逐层预训练和整体微调的方式使深层次的神经网络的训练成为了可能。在深度学习技术的推动下,计算机视觉由原先精度低、复杂性高、人为干预多的情况进入了发展的新时代。
卷积神经网络(CNN)是最常用于计算机视觉的深度学习技术之一。CNN 借鉴了生物视觉的有关概念。网络像生物视觉器官一样逐层从输入中提取局部特征并在高层次进行汇总,最终完成对输入的模式识别。除 DBN 和 CNN 外,递归神经网络(RNN)、堆栈自编码器(SAE)等深度学习技术也在计算机视觉等方面得到许多应用。
在之后的时间里,其他深度网络模型如雨后春笋一般涌现。各种深度学习模型被广泛运用在计算机视觉中,为计算机视觉带来了一场革命。以人脸识别为例,在深度学习技术出现之前,人脸识别方法以模板匹配法、基于特征的方法、基于连接的方法等传统技术为主。这些技术存在易受表情影响、所提取特征质量较差等问题。
深度学习出现后,人脸识别研究迎来了新的高潮。在很短的时间内,深度学习技术就将人脸识别的准确率提高到了 99%以上。在深度学习的浪潮下,一批优秀的计算机视觉相关的企业相继诞生。
计算机“睁眼看世界”
计算机视觉(Computer Vision, CV)是一门研究如何让计算机实现人类视觉系统功能的学科。人类的视觉系统主要分为眼球作用区和大脑作用区。其中眼球作用区负责将视频景物转换为大脑中的电信号,而大脑作用区则将电信号进一步转变为感知。通过以成像设备和系统替代视觉器官,并以计算机替代大脑完成视觉输入的理解和处理,CV 技术能够完成对人类视觉系统的模拟,从而实现适应、理解外界环境和控制自身运动等复杂的智能功能。
人类视觉系统与计算机视觉系统对比

资料来源:中国报告网整理
作为人工智能的重要分支之一,计算机视觉与语音识别、语言识别等技术一同构成了人工智能的感知基础。它让计算机能够“睁眼看世界”。斯坦福大学教授李飞飞将这种“看”的能力称作“计算机科学领域最前沿的、具有革命性潜力的科技”。作为人的感官的延伸,计算机视觉将被广泛应用于图像识别、人脸检测、人脸识别等方面,并逐步渗透到无人驾驶、安防、机器人、智能家居等众多领域中。可以预见,在不久的将来,计算机视觉技术将会成为许多行业发展的新动力。
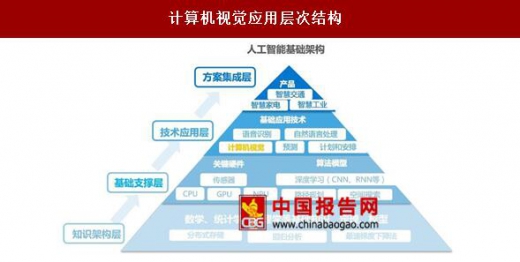
计算机视觉应用层次结构

资料来源:中国报告网整理
尽管计算机视觉从诞生至今已经历了 50 余年的发展,该领域依然存在一些有待解决的问题。例如如何高效准确地识别目标、如何有效地构造易于实现的识别算法、如何解决实时性和稳定性问题等。这些问题也将成为计算机视觉企业的发展机遇。现在已有部分优质企业在应用方面对这些问题给出了一些解决方案。展望计算机视觉技术的未来,图像特征选择、动态性能提升等方面将会成为重点的研究方向。
诞生——来自人工智能之父的 CV 元年
1966 年被称作计算机视觉元年。尽管在此之前的 20 世纪 50 年代中,学者们已经将计算机视觉的有关技术作为统计模式识别部分内容进行了研究,但研究的内容主要集中在光学字符、显微图谱、航空图片等二维图像的分析和研究中,并且计算机视觉在此时尚未成成为一门独立的学科。在 1966 年的夏天,著名的人工智能学者马文明斯基(Marvin Lee Minsky)要求其学生通过编程让计算机告诉使用者摄像头所拍摄的内容。这一任务触及到了计算机视觉的本质之一,也标志着计算机视觉的诞生。
人工智能之父——马文明斯基

资料来源:中国报告网整理
Larry Roberts 发表了计算机视觉领域的第一篇博士论文《Machine Perception of Three-Dimensional Solids》。Roberts 将现实世界简化为由简单的三维结构所组成的“积木世界”,并且使用计算机从“积木世界”中提取出了立方体、棱柱等多种三维结构。此外,Roberts 还对物体的形状和空间关系做出了描述。对“积木世界”的研究是计算机视觉早期的重要尝试。它使人们相信,对简单的“积木世界”的理解能够推广到更复杂的现实世界中,并最终彻底实现人类视觉系统的完全替代。
繁荣——始于理论框架的建立
随后计算机视觉进入了蓬勃发展的时代。B. K. P. Horn 教授于 20 世纪 70 年代中期在 MIT 的人工智能实验室正式开设了“计算机视觉”课程。这成为了计算机视觉史上的标志性事件之一。后来人工智能实验室的 David Marr 教授提出了著名的计算视觉理论。该理论认为人类视觉的主要功能是复原三维场景的可见几何表面,即三维重建问题,并且这种从二维图像到三维几何结构的复原过程可以通过计算完成。理论强调从不同阶段去研究时间信息处理的问题。这一理论至今仍旧是计算机视觉研究的基本框架。
计算视觉理论三阶段

资料来源:中国报告网整理
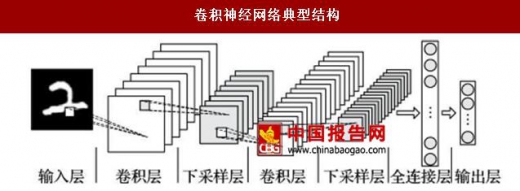
20 世纪 80 年代后,计算机视觉技术又迈上了一个新的台阶。著名的卷积神经网络的实现在此期间诞生。卷积神经网络的理论基础是生物视觉中的“局部感受野”概念。生物在利用视觉识别物体的过程中并非显式地从图像中提取特征,而是通过一个自组织的深层网络结构逐层地将前一层信息抽象化。每一个视觉神经元都不感知图像的整体而只感受图像的局部信息。各个神经元感知的局部特征在神经网络的更高层级中综合时,生物就能够感知到图像的全局信息。图像局部感知能够保证图像发生平移或形变时图像的关键特征依然可以准确地被提取。
卷积神经网络典型结构

资料来源:中国报告网整理
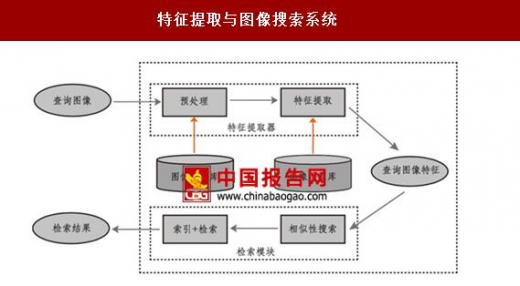
除了实现卷积神经网络外,主动视觉、目的视觉、重建理论、基于学习的视觉等重要的计算机视觉理论体系均在随后诞生。各类新方法和新理论的出现为计算机视觉带来了前所未有的繁荣。90 年代起,各类统计学习方法开始逐渐流行。统计学习通过统计方法提取了物体的局部特征。这些局部特征不同于形状、纹理等全局特征,不会犹豫平移或视角的改变而生剧烈的变化,因此具备了一定的特征旋转和平移不变性。基于局部特征,人们可以建立不同物品的局部特征集,从而实现类似物品的检索。图像搜索等技术正是因此得以发展。
特征提取与图像搜索系统

资料来源:中国报告网整理
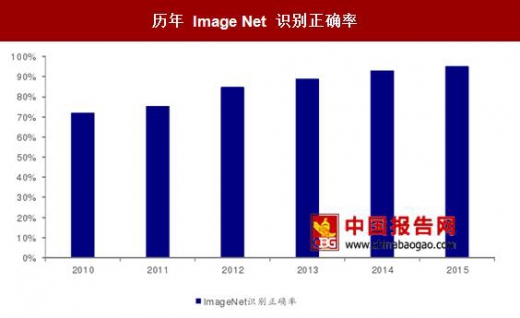
突破——深度学习将计算机视觉带入新时代 进入 21 世纪后,机器学习开始大行其道。“机器学习”一词源自 IBM 的一篇论文,指利用计算机实现或模仿人类的学习行为。机器学习技术不同于先前使用的方法。它无需人为设计和提取特征,而是通过特定的算法从大量的样本中自动归纳学习。机器学习的应用需要大量的数据样本来支撑,而 2000 年以来的互联网技术的飞速发展为机器学习技术提供了所需的海量数据。例如,著名的 ImageNet 数据集包含了 2 万多个类别供 1400 万张图片。此数据集是世界上最大的图像识别数据库,计算机视觉研究人员将其作为重要的数据来源之一,开发人员不约而同地将模型在 ImageNet 上的识别准确率作为比较基准。研究者们在该数据集训练了 AlexNet、GoogleNet 等著名的模型,并且不断刷新着物体识别的准确率。
历年 Image Net 识别正确率

数据来源:中国报告网整理
在 2006 年之前,计算机视觉中所使用的模式识别方法主要是机器学习中的浅层学习技术,如支持向量机、决策树等。这些方法存在特征提取能力不足、容易出现过拟合等问题。2006 年,Hinton 等人提出了深度臵信网络模型(DBN)。DBN 是深度学习领域的第一个模型。它通过将多个受限波尔茨曼机(RBM)堆叠成为一个深度网络结构,获得了浅层模型难以比拟的高层次抽象特征提取能力,从而具备了更加优越的性能。此模型通过逐层预训练和整体微调的方式使深层次的神经网络的训练成为了可能。在深度学习技术的推动下,计算机视觉由原先精度低、复杂性高、人为干预多的情况进入了发展的新时代。
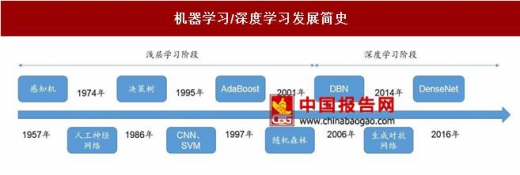
机器学习/深度学习发展简史

资料来源:中国报告网整理
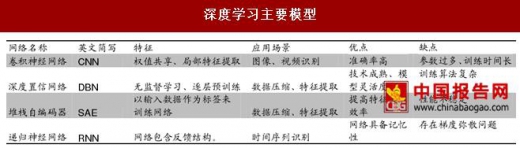
卷积神经网络(CNN)是最常用于计算机视觉的深度学习技术之一。CNN 借鉴了生物视觉的有关概念。网络像生物视觉器官一样逐层从输入中提取局部特征并在高层次进行汇总,最终完成对输入的模式识别。除 DBN 和 CNN 外,递归神经网络(RNN)、堆栈自编码器(SAE)等深度学习技术也在计算机视觉等方面得到许多应用。
深度学习主要模型

资料来源:中国报告网整理
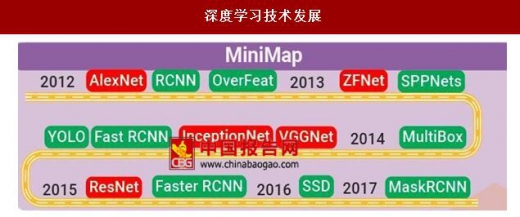
在之后的时间里,其他深度网络模型如雨后春笋一般涌现。各种深度学习模型被广泛运用在计算机视觉中,为计算机视觉带来了一场革命。以人脸识别为例,在深度学习技术出现之前,人脸识别方法以模板匹配法、基于特征的方法、基于连接的方法等传统技术为主。这些技术存在易受表情影响、所提取特征质量较差等问题。
深度学习技术发展

资料来源:中国报告网整理
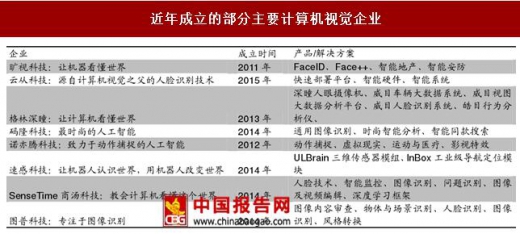
深度学习出现后,人脸识别研究迎来了新的高潮。在很短的时间内,深度学习技术就将人脸识别的准确率提高到了 99%以上。在深度学习的浪潮下,一批优秀的计算机视觉相关的企业相继诞生。
近年成立的部分主要计算机视觉企业

资料来源:中国报告网整理
资料来源:国家统计局,中国报告网整理,转载请注明出处(ZQ)
更多好文每日分享,欢迎关注公众号

【版权提示】观研报告网倡导尊重与保护知识产权。未经许可,任何人不得复制、转载、或以其他方式使用本网站的内容。如发现本站文章存在版权问题,烦请提供版权疑问、身份证明、版权证明、联系方式等发邮件至kf@chinabaogao.com,我们将及时沟通与处理。








